In the realm of artificial intelligence and machine learning, data is the lifeblood that fuels innovation and progress. However, raw data alone is often insufficient for training and fine-tuning machine learning models. This is where data annotation comes into play. Data annotation is a critical step in the machine learning pipeline that involves labeling and structuring data to make it understandable and usable for algorithms.
What is Data Annotation and its types?
Data annotation is the process of adding metadata, labels, or tags to data, typically in the form of text, images, videos, or other types of information. The purpose of data annotation is to make the data understandable and usable for machines, particularly for training and fine-tuning machine learning and artificial intelligence algorithms. Annotation involves providing additional context or information about specific elements within the data, such as identifying objects in images, labeling text for sentiment analysis, or marking key features in videos.
Here are some common examples of types of data annotation:
Image Annotation: In image annotation, labels or bounding boxes are added to identify and locate objects or regions of interest within images. This is commonly used in computer vision tasks like object detection or image classification.
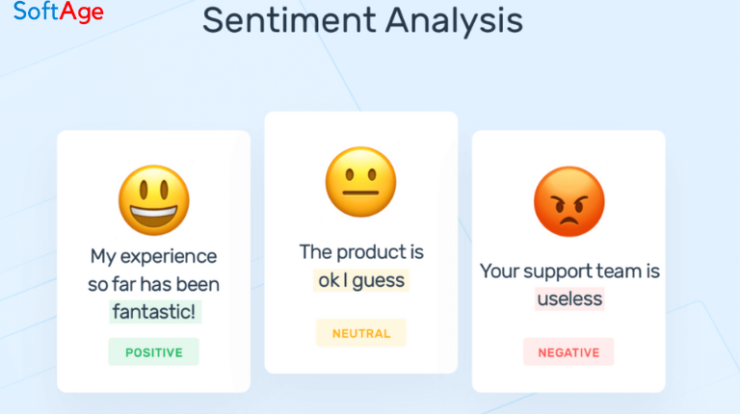
Text Annotation: Text data can be annotated with labels or tags to indicate sentiment, entity recognition (e.g., identifying names of people or places), part-of-speech tags, or any other relevant information for natural language processing tasks.
Audio Annotation: Audio data can be annotated by adding transcriptions, timestamps, or labels to identify spoken words, sounds, or music genres. This is important for tasks like speech recognition or audio classification.
Video Annotation: Video data often requires temporal annotations to track objects or events over time. This can include annotating video frames with bounding boxes, object tracking, or activity recognition.
Geospatial Annotation: Geographic data, such as maps, satellite images, or location-based data, can be annotated with information like landmarks, boundaries, or geographic features.
The Importance of Data Annotation:
Data annotation is of paramount importance in the field of machine learning and artificial intelligence (AI). It serves as the foundation upon which many AI models and algorithms are built. Here are several key reasons why data annotation is crucial:
Training Machine Learning Models: Supervised machine learning models require labeled data for training. Data annotation provides the ground truth or correct answers that models learn from. Accurate and high-quality annotations are essential for building models that make reliable predictions.
Supporting Object Detection and Recognition: In computer vision, data annotation involves labeling objects, regions, or features within images or videos. This is essential for applications like object detection, image segmentation, and facial recognition.
Enhancing Natural Language Processing (NLP): Annotated text data is crucial for training NLP models. Annotations can include sentiment labels, named entities, part-of-speech tags, and more, enabling machines to understand and process human language.
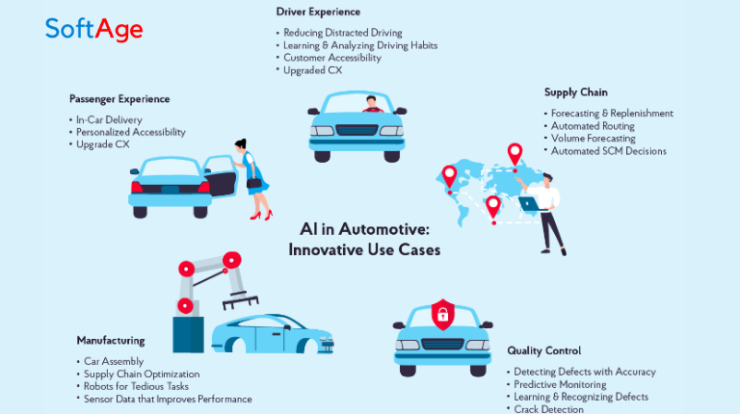
Enabling Autonomous Systems: In fields like autonomous vehicles and robotics, data annotation helps machines perceive and navigate the physical world. Annotated data is critical for tasks like object detection, path planning, and collision avoidance.
Medical Diagnosis and Healthcare: Annotated medical images, such as X-rays and MRIs, assist in diagnosing diseases and conditions. Annotations help identify abnormalities and provide valuable insights to healthcare professionals.
E-commerce and Personalization: Annotated data supports recommendation systems by understanding user preferences and behavior. This leads to more accurate product recommendations and personalized experiences.
Research and Innovation: Data annotation plays a pivotal role in advancing research and innovation in various fields, from climate science to social sciences. Annotated data supports data-driven discoveries and breakthroughs.
The Challenges of Data Annotation:
Data annotation is a critical and often challenging step in preparing data for machine learning and artificial intelligence applications. While it is essential for training accurate and effective models, data annotation comes with several challenges that need to be addressed. Here are some of the key challenges of data annotation:
Subjectivity and Annotator Bias: Data annotation often involves subjective judgments, such as sentiment analysis or image categorization. Annotators may have different interpretations or personal biases, leading to inconsistent annotations. Maintaining consistency and minimizing bias is a constant challenge.
Annotation Quality: Ensuring the quality and accuracy of annotations is crucial. Annotator errors or inconsistencies can lead to misleading training data and negatively impact model performance. Quality control measures and guidelines are necessary to maintain annotation standards.
Scalability: Annotating large datasets can be time-consuming and expensive. Scaling annotation efforts to handle big data is a significant challenge. Efficient annotation tools and strategies are needed to keep up with the volume of data.
Privacy and Security: Annotating sensitive or private data, such as personal information in text or identifiable individuals in images, requires strict adherence to privacy regulations. Anonymizing data and securing it during annotation is a challenge.
Data Labeling Costs: Data annotation can be expensive, particularly when skilled annotators are needed. The cost of labeling large datasets can be a barrier to some projects, especially for start-ups or organizations with limited resources.
Consistency across Annotators: When multiple annotators work on the same dataset, ensuring consistency in annotations can be challenging. Inter-annotator agreement metrics and ongoing training help address this issue.